Industry news
深度学习中常用的优化器
- Stochastic Gradient Descent(SGD)
- Momentum
- Adagrad
- RMSprop
- Adam
- AdaMax
假设梯度下降法是一个下山的过程。
假设这样一个场景:一个人被困在山上,需要从山上下来(找到山的最低点,也就是山谷)。但此时山上的浓雾很大,导致可视度很低;因此,下山的路径就无法确定,必须利用自己周围的信息一步一步地找到下山的路。这个时候,便可利用梯度下降算法来帮助自己下山。怎么做呢,首先以他当前的所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着下降方向走一步,然后又继续以当前位置为基准,再找最陡峭的地方,再走直到最后到达最低处;同理上山也是如此,只是这时候就变成梯度上升算法了。
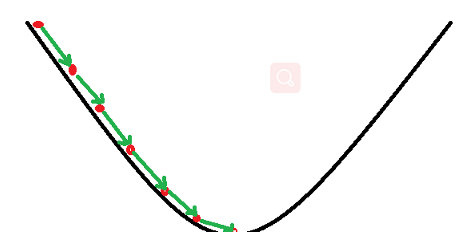
?


普通的方法,就是重复不断的把整套数据放入神经网络NN训练,这样消耗的计算资料较大
而SGD的方法则是将数据拆封成小批小批的, 然后在分批不断的放入NN中进行计算
Batch Gradient Descent 对大型数据集有大量的冗余计算,因为它会在每个参数更新前重新计算相似的梯度。而 SGD 针对每个样本进行一次参数更新。SGD 针对每个样本进行一次参数更新。由于 SGD 频繁执行更新,且变化很大,这导致目标函数震荡十分剧烈 。同时也会带来一定的好处,有可能收敛到局部最小值的可能性。
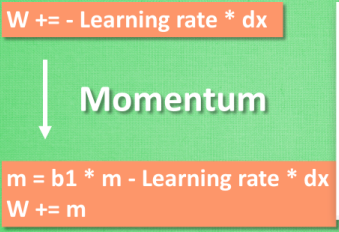
Momentum动量:
我们将最小化目函数的任务比作下山,SGD难以在沟壑中移动,在局部上有些维度的弯曲程度会比下山的弯曲程序要多的多,这样就很容易使SGD陷入局部最优解。这样SGD会在局部位置缓慢的更新梯度。
Momentunm 相当于在SGD的基础上施加了一层动量。并且这个动量惯性不断的累加。
这样动量参数对于梯度往相同方向前进促进,而对梯度改变方向时进行抑制(惯性带来阻力)这样我们就获得了更快的收敛和减少了SGD本身的震荡。

?
AdaGrad的核心思想是,深度模型带来的稀疏性,导致模型中一些参数可能频繁获得较大梯度,另外一些参数可能偶尔获得较大梯度,如果采用同一种学习率将会导致后者更新非常缓慢,所以可以调节模型中不同参数的学习率,而不使用统一的学习率,如果一个参数的历史累计梯度更新量大,那么降低该参数的学习率,如果一个参数的历史累计梯度更新小,则增大该参数的学习率。
?
Adagrad算法的一个主要优点是无需手动调整学习率。在大多数的应用场景中,通常采用0.01。
? Adagrad的一个主要缺点是它在分母中累加梯度的平方:由于没增加一个正项,在整个训练过程中,累加的和会持续增长。这会导致学习率变小以至于最终变得无限小,在学习率无限小时,Adagrad算法将无法取得额外的信息。
Adagrad算法的话相当于施加了一层阻力。
Momentum算法的话相当于施加了一层推了
也属于自适应梯度范畴。区别于adagrad之处是它采用了EMA方式来统计每个参数的最近的累计梯度量,所以多次迭代后不会导致模型参数更新缓慢。
该算法需要给每一个待更新的模型参数设置一个累计梯度统计量?vt?、一个自适应梯度的动量?bt?,所以额外的内存/显存消耗是,2倍的模型参数量
Adam优化器结合了AdaGrad和RMSProp两种优化算法的优点。
?在adam中,一阶矩来控制模型更新的方向,二阶矩控制步长(学习率)。利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。
- 实现简单,计算高效,对内存需求少。
- 参数的更新不受梯度的伸缩变换影响。
- 超参数具有很好的解释性,且通常无需调整或仅需很少的微调。
- 更新的步长能够被限制在大致的范围内(初始学习率)。
- 能自然地实现步长退火过程(自动调整学习率)。
- 很适合应用于大规模的数据及参数的场景。
- 适用于不稳定目标函数。
- 适用于梯度稀疏或梯度存在很大噪声的问题。
?AdamW优化器修正了Adam中权重衰减的bug,
因为Adam的学习率自适应的,而L2正则遇到自适应学习率后效果不理想,所以使用adam+权重衰减的方式解决问题。
| SGD | 没有自适应学习率机制,但仔细调参最终模型效果可能最好 | 最多1倍模型参数量 |
| Adam | 学习率相对不敏感,减少调参试验代价,但weight decay实现不好,能用Adam的地方可以都用AdamW来代替 | 最多3倍模型参数量 |
| AdamW | 相对于Adam,weight decay实现解耦,效果更好 | 最多3倍模型参数量 |
Categories
富联新闻
Contact Us
Contact: 富联娱乐-富联全球导航站
Phone: 13800000000
Tel: 400-123-4567
E-mail: admin@youweb.com
Add: Here is your company address

